Local AI assistants
I’ve been playing around with local AI assistants lately, comparing them to ChatGPT and Bard for coding and general questions. While they can perform on par or close to their commercial counterparts, I found them useful, even potentially ready as daily assistants to avoid repetitive tasks.
Note: my tests have been “ad hoc” and merelly from the point of view of user experience. Nothing too scientific here.
There are now a few tools out in the wild, but the one I focused now is “Ollama”.
Ollama as code assistant
I installed Ollama with some models to help me research and code. I also tried two plugins for Visual Studio Code, removing TabNine and Copilot. While there wasn’t a big difference, I found them useful in my everyday tasks by inferring and completing my code.
When I asked the CodeLlama model from my terminal window what are the benefits of a Local AI assistant, this is what it answered:
>>> What are the benefits of using a local AI assistant for coding? Please be brief.
The benefits of using a local AI assistant for coding include:
* Faster response time compared to commercial assistants
* Personalized suggestions based on your specific needs and code style
* Ability to use them in your daily activities, such as completing repetitive tasks or solving small problems.
All that is in theory. I believe that for each use case the milleage will vary.
Installation and first steps
I work on Linux and Windows, and I’m surprised at how easy the community made the use of these tools. For Windows users, follow these steps in WSL (Windows Subsystem for Linux) to get started. The hardware requirements for your machine will impact performance. Try small models first, so the performance does not dissapoint. Larger models do require significant RAM, CPU and Graphic Card resources.
The installation from the terminal is quite simple:
- Install the ollama service with this command
curl -fsSL https://ollama.com/install.sh | sh(Source) - Choose your model from the Ollama library page (CodeLlama)
- Run the model with this command to use the codellama model:
ollama run codellama
Ollama downloading and running the CodeLlama model.
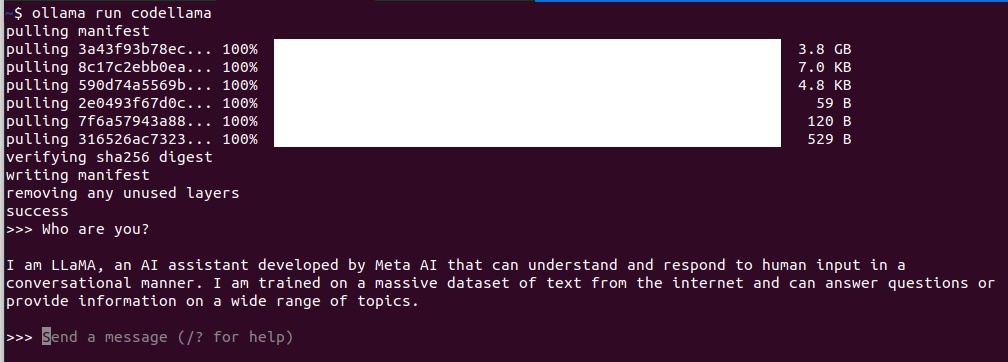
- At the prompt, type your questions to see the answer generated in real time.
Ollama runs models to generate responses. Models are pre-trained datasets that make up the AI’s “brain”. There are many different models available, each focused on a specific task or topic, from coding to Shakespeare and anything in between.
Some basic commands
Here are some basic commands to manage the tool from the terminal:
| Description | Command |
|---|---|
| Start Ollama server | ollama serve |
| Stop Ollama server | CTRL + C |
| List models installed | ollama list |
| Run a model | ollama run [modelname] |
| Exit AI prompt and return to terminal | /bye |
| Delete a model | ollama rm [modelname] |
| Enable Ollama to start at boot | sudo systemctl enable ollama |
| Disable automatic start of Ollama (Ubuntu/Debian) | sudo systemctl disable ollama |
Check the ollama blog and help for more useful commands at the Ollama website.
Developer tools
As of today, there are some very promising extensions to Visual Studio Code that connect to the ollama server (local or remote). More are coming all the time, so expect more goodies from the community soon. In particular, I found useful these:
- Continue-CodeLlama, GPT-4, and more: an extension that provides you with a chat interface to Ollama/CodeLlama and other commercial AIs, directly in your IDE.
- Llama Coder: an extension that focuses on providing you with code completion, based on your own code and infered logic.
Recommended content
If you are interested in knowing more in depth about this topic, I recommend these YouTube channels:
- Matt Williams, one of the maintainers of the Ollama code.
- Matthew Berman, an advocate and educator of all things AI.
Both channels offer information, tutorials, and news about this developing world.
Conclusion
I can’t say that I find these tools to be life changers, but they do make a good addition to my coding workflow. My opinion may change with more time using them, and I still consider my job safe.